Introduction
Welcome to part one of the x86 Linux binary exploitation series. In these series of posts, I will cover x86 Linux binary exploitation, from basics to advanced topics.
All of the exercises in these articles can be done in a virtual environment. Tools that I will be using are:
- gef (GDB plugin): https://github.com/hugsy/gef
- readelf: https://linux.die.net/man/1/readelf
- objdump: https://linux.die.net/man/1/objdump
- Ubuntu 32 bit version
Understanding the Basics
Before jumping into all the good stuff we need to go through some basics like what is registers, stack and assembly this will help us to understand the exploit development process better.
First, a basic understanding of assembly will be helpful to be able to make sense of all of this. In-depth coverage of assembly code is way out of scope for this article, I will leave some reference materials here, so you can go through it.
x86 Assembly Crash course is an excellent intro to assembly.
Memory Layout
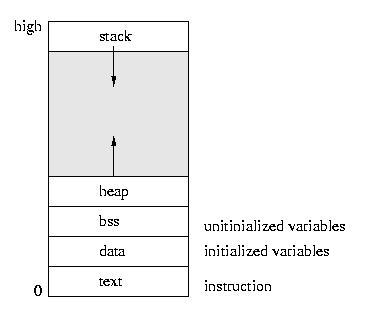
- The text section stores the program executable.
- The data section stores initialized data.
- The bss section stores uninitialized data.
- The heap section is a memory that you can dynamically reserve from calling malloc.
- The stack section is a memory that functions and local variables are stored.
Assembly instruction set introduced in 1978 by Intel
- 1978 16bit
- 1985 32bit
- 2001 64bit (Itanium)
- 2003 64bit (AMD64)
Important Registers
A register is a location within the processor that is able to store data. For exploit development the following special-purpose registers are important.
- ESP: Stack pointer, “top” of the current stack frame
- EBP: Base pointer, “bottom” of the current stack frame
- EIP: Instruction pointer, a pointer to the next instruction to be executed by the CPU
What is a Buffer Overflow?
A stack overflow occurs when a program stores more data in a variable on the execution stack than is allocated to the variable. The excess data corrupts nearby space in memory and may alter other data. As a result, the program might report an error or behave differently. Using unsafe functions that can lead to a buffer overflow vulnerability: printf, sprintf, strcat, strcpy, and gets.
Bug Classes
There are many different possible attack vectors in today’s native binaries. I will cover some of these in this series.
- Stack Buffer Overflows
- Heap Buffer Overflows
- Format String Attacks
- Use After Free (UAF)
Now that we have some idea about binary exploitation, let’s do a simple practical example. This code is from protorstar0, the goal of this challenge is to modify the value of the “modified” variable, which is now equal to 0.
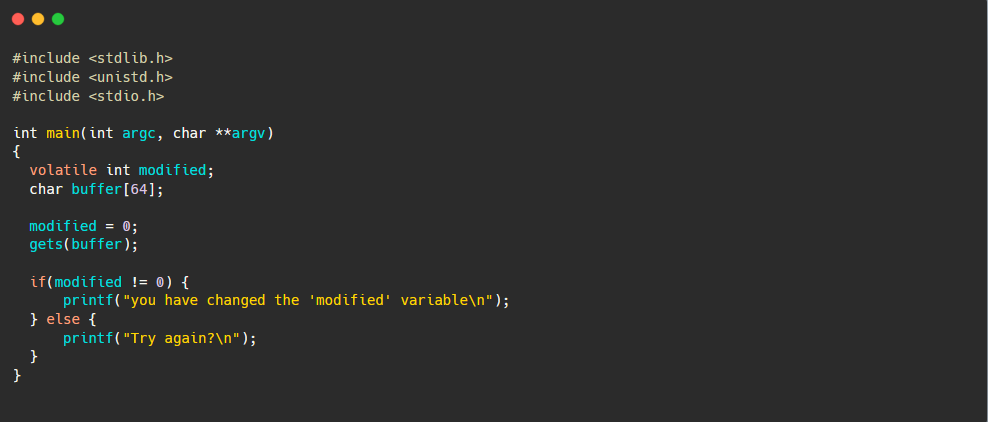
From the code we can see a 64-byte buffer is in the program, we can modify it because of unsafe gets function used. The get() function allows overriding the declared buffer size.
The gets() doesn’t do any array bound checking, that’s why it is considered as an unsafe function. To avoid Buffer Overflow, fgets() should be used instead of gets().
Now let’s compile the above code and open the binary in DGB. Before compiling the code, let’s disable some of the exploit mitigation mechanisms in place.
`echo 0 | sudo tee /proc/sys/kernel/randomize_va_space` Compile the binary
compile the code using the following flags
`gcc -fno-stack-protector -o <vuln> vuln.c`
-fno-stack-protector : `Emit extra code to check for buffer overflows` After compiling the binary, let’s check the properties of executables, if there is any exploit mitigations (like PIE, RELRO, PaX, Canaries, ASLR ).

Open the binary in GDB

Let’s send some data to the program

We got a reply try Again, We know the defined buffer size is 64 bytes. Let’s send more than 64 bytes of data and monitor the program in GDB
 </figure>
</figure>
As we can see from GDB output program get a segmentation fault when receiving more than 64 bytes of data. The variable modified get overwrite and other important registers are overwritten.
This is a very simple example of how we can take advantage of vulnerable functions used in programs to exploit them. That’s it for this intro article,